
Introduction
A rite of passage in understanding machine learning is writing your own network from scratch. This isn’t usually about making a better framework, it’s about figuring out what’s going on in all those frameworks. What follows is my contribution to this small but growing genre of programming literature.
The code is based on Andrew Trask’s Grokking Deep Learning (Github), which I’ll refer to as GDL below. No, I haven’t finished it, but this is the first major milestone, so I’m documenting it before I forget.
My background is that of a developer. I have been programming for a living since the 1980’s, mostly across the Object-Oriented landscape. I like classes and generalized solutions. It’s how I think, so this will be the framing that I use for this example.
There are two files: SimpleLayer.py, a class that handles the particulars of what a layer in a network needs to do, and simple_nn.py, a file that exercises that class by building a three-layer NN. We’ll walk through simple_nn.py first, which sets up and runs the network. Then we’ll walk through SimpleLayer, which handles training and backpropagation. At the bottom of the post are full code listings, which are also available on GitHub if you want to use this as a basis for experimentation.
simple_nn.py
Let’s start at the beginning:
import numpy as np import matplotlib.pyplot as plt import src.SimpleLayer as sl
One of the things that I try to do in these sort of exercises is to keep the amount of libraries to a minimum. For this I use two very vanilla imports, NumPy for math, and Matplotlib for diagrams of the weights changing over time.
Next, some global variables:
# variables ------------------------------------------ # The samples. Columns are the things we're sampling, rows are the samples streetlights_array = np.array( [[ 1, 0, 1 ], [ 0, 1, 1 ], [ 0, 0, 1 ], [ 1, 1, 1 ]]) num_streetlights = len(streetlights_array[0]) num_samples = len(streetlights_array) # The data set we want to map to. Each entry in the array matches the corresponding streetlights_array row walk_vs_stop_array = np.array([[1], [1], [0], [0]])
Here is all the data about the lights. Each row is a sample. Each element in the row is a light. There are four rows in this set. They are matched to a classification of each row in the walk/stop array. These values come from GDL, where the premise is that you have a set of samples from three lights (streetlight_array), and a set of samples of actions that happen (walk_vs_stop_array).

Figure 1: The lights and the behaviors from GDL
The goal is to train a network from the input streetlights that produces the right walk/stop output. Now in a real network, we’d worry about overfitting and other related issues, but we’re going to ignore that here.
The next two variables are not in GDL. These are layer_array, which will contain the instances of the SimpleLayer class, and error_plot_mat, which will be used by pyplot to draw a chart of the error converging to zero. Or failing to, as the case may be.
# set up the dictionary that will store the numpy weight matrices layer_array = [] error_plot_mat = [] # for drawing plots
There is one last bit of setup before we start doing things. There are three methods that will be used later in the program:
# Methods ---------------------------------------------
# activation function: sets all negative numbers to zero
# Otherwise returns x
def relu(x: np.array) -> np.array :
return (x > 0) * x
# This is the derivative of the above relu function, since the derivative of 1x is 1
def relu2deriv(output: np.array) -> np.array:
return 1.0*(output > 0) # returns 1 for input > 0
# return 0 otherwise
# create a layer
def create_layer(layer_name: str, neuron_count: int, target: sl.SimpleLayer = None) -> 'SimpleLayer':
layer = sl.SimpleLayer(layer_name, neuron_count, relu, relu2deriv, target)
layer_array.append(layer)
return layer
Let’s go through these one at a time. First, I’d like to say that as someone who likes compiling, strong typing, and all those components that keep me from doing dumb things, I am a fan of Python’s accommodation of typing. It could be better, but it helps:
- def relu(x: np.array) -> np.array :
- This is an example of an activation function. It will be used in the layer to determine whether or not a value propagates through the neuron. In this case, all it does is clamp negative values to zero.
- def relu2deriv(output: np.array) -> np.array:
- This is the inverse of the above function, and returns a one (the slope of the line in relu()) if the value is greater than zero.
- def create_layer(layer_name: str, neuron_count: int, target: sl.SimpleLayer = None) -> ‘SimpleLayer’:
- This is what I use to create a layer. You pass in the name for your layer, how many neurons it has, and its ‘target’, or the layer below it. One of the things that I discovered when writing the SimpleLayer class is how intimately layers are connected. In this case, building any other layer than the last requires a target layer. This allows the weights that will manage the influence between the neurons in each layer to be set up properly. It could have just as easily been built from top to bottom, and pointed at the ‘source’ layer.
- The other thing that this method does is to store the newly created layer in the layer_array, which makes experimenting with adding and deleting layers trivial.
Ok, let’s set up the layers in our network! Again, this is a reimplementation of the network built in GDL (chapter 6)
np.random.seed(0)
#set up the layers from last to first, so that there is a target layer
output = create_layer("output", 1)
output.set_neurons([1])
hidden = create_layer("hidden", 4, output)
hidden.set_neurons([1, 2, 3, 4])
input = create_layer("input", 3, hidden)
input.set_neurons([1, 2, 3])
for layer in reversed(layer_array):
print ("--------------")
print (layer.to_string())
First, we seed the random generator with a value so that these results are repeatable. It turns out that this network can be made to converge very fast or not to converge simply by picking a different seed. We’ll discuss what this implies later.
So what we’ve created is a stack of layers, built from bottom to top that looks like this:
- Input layer (3 neurons): This is where the streetlights information will be loaded
- Hidden layer (4 neurons): This layer mediates the interactions between the input and output layers, making these interactions nonlinear. It’s what allows deep neural networks to learn nonlinear, discontinuous functions from examples (And remember, that’s all that neural networks do. Though to be fair, it may be all our brains do, too…
- Output layer (1 neuron): This is where the walk/stop values will be used to adjust the output that is generated starting with the original, random weights.
We then print out the contents of each layer. One quick note – I load the neurons up with sequential integers (e.g. [[1. 2. 3.]]). These values get overridden when the system is run, so it’s just a way to quickly verify the as-built neurons :
-------------- layer input: target = hidden source = no source neurons (row) = [[1. 2. 3.]] weights (row) = [[-0.1526904 0.29178823 -0.12482558 0.783546 ] [ 0.92732552 -0.23311696 0.58345008 0.05778984] [ 0.13608912 0.85119328 -0.85792788 -0.8257414 ]] -------------- layer hidden: target = output source = input neurons (row) = [[1. 2. 3. 4.]] weights (row) = [[0.09762701] [0.43037873] [0.20552675] [0.08976637]] -------------- layer output: target = no target source = hidden neurons (row) = [[1.]] weights (row) = None
I think this output is pretty obvious, aside from the weights, so let’s look at them more closely. But first, a short digression.
Normally when I see diagrams and descriptions of connected layers of neurons, I usually see something like this:

Figure 2: The typical neural network diagram
As you can see, each neuron in the input layer is connected to each neuron in the hidden layer and so on through to the output layer. And that’s nice conceptually, but as a developer, I have no understanding of the mechanics of what’s happening. Here’s what it really looks like. For clarity, only the interactions involving input neuron 1 and hidden neuron 4 are shown, but the process is identical:
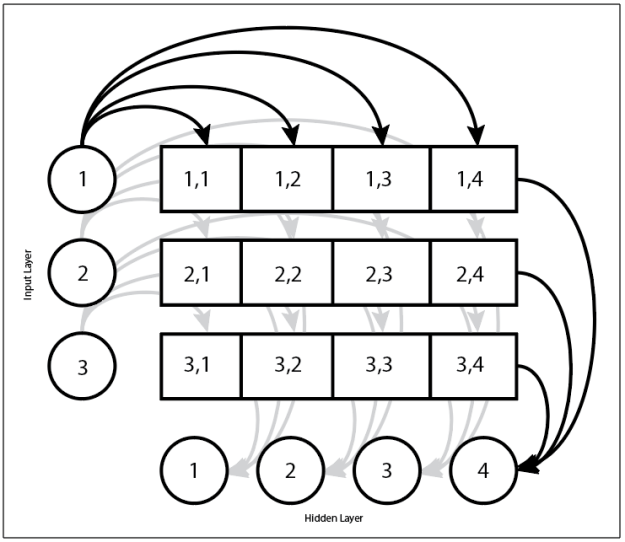
Figure 3: How the input and hidden layer are actually connected
In this case, we’re looking at the mapping between the input layer and the hidden layer. Each neuron in the input layer gets its own row of weights, let’s say [0.1, 0.2, 0.0, 0.5] for neuron one. If that neuron is set to “10”, then a value of 1.0 will go to hidden neuron 1, a value of 2 to hidden neuron 2, and a value of 5 to hidden neuron 4. This process is repeated for each neuron in the input layer, and the value is added to the associated hidden neuron.
That’s what we mean when we talk about fully connected layers. Everything is mediated through an adjacency matrix of weights. We’ll revisit this in more detail when we walk through SimpleLayer. So in the listing above the two figures, the randomly initialized weights are organized so that the each neuron in the layer has its own row. Each entry in that row is the scalar value that the row’s neuron value will be multiplied by as it is accumulated in the target’s neuron. Source neurons are the row component. Target neurons are the column component.
Next is the body of the program:
alpha = 0.2
iter = 0
max_iter = 1000
epsilon = 0.001
error = 2 * epsilon
while error > epsilon:
error = 0
for sample_index in range(num_samples):
input.set_neurons(streetlights_array[sample_index])
for layer in reversed(layer_array):
layer.train()
delta = output.calc_delta(walk_vs_stop_array[sample_index])
sample_error = np.sum(delta ** 2)
error += sample_error
for layer in layer_array:
layer.learn(alpha)
# Gather data for the plots
error_plot_mat.append([sample_error])
# print("{}.{} Error = {:.5f}".format(iter, sample_index, sample_error))
error /= num_samples
if (iter % 10) == 0 :
print("{} Error = {:.5f}".format(iter, error))
iter += 1
# stop even if we don't converge
if iter > max_iter:
break
Let’s talk about the local variables first. The first variable, alpha, is the learning rate that we pass in. It’s a scalar that limits the step size in the change in weights. The bigger the scalar, the more likely to overshoot the goal and go into oscillation around it. The smaller the goal, the longer the approach will take, but the greater the chance that it will stabilize. Like the seed we use to set the random number generator, the number of layers, and the number of neurons per layer, this is a hyperparameter. Some, like alpha, result in predictable behavior. Others, like seed, do not. There is a lot of this in deep learning, and you need to be careful about it. In particular, testing the resiliency of the solution by running it with a variety of nonlinear hyperparameters to see if the results are consistent is probably a good idea, though it sucks up compute resources.
The rest of the variables are used for loop control:
- iter is the current count of times through the loop
- max_iter is the maximum times we’ll run through the loop, even if we don’t converge
- epsilon is the error threshold. If the error drops below that, we’re done.
- error is the sum of the squares of all the output neurons (in this case, one). We initialize it to a value that gets us into the loop
while error > epsilon:
error = 0
sample_error_array = []
for sample_index in range(num_samples):
input.set_neurons(streetlights_array[sample_index])
This is the main loop. First, we’re going to loop until our error is small. Error is computed by sample, so we need to know what the average (or max – I use average here) error is for each iteration. We also want to save the individual errors by sample for later plotting.
Within each loop, we’re going to evaluate the input streetlights sample against the output walk/stop sample. The first step in this process is to set the input neurons. This is where the input.set_neurons([1, 2, 3]) that we did when we were creating the layers gets overridden. In the training, the output from this layer will overwrite the values in the next layer and so on.
for layer in reversed(layer_array):
layer.train()
This is the training step. We’ll go into more detail when we walk through SimpleLayer, but for now not that we set through all the layers from the top to the bottom, in reversed order from how they were created and loaded into layer_array.
delta = output.calc_delta(walk_vs_stop_array[sample_index]) sample_error = np.sum(delta ** 2) error += sample_error
This is where we calculate the array of deltas that are the difference between the goal of the walk/stop array and the output neurons. the error is the sum of the squares of all those deltas. SoS is nice because it’s always positive.
for layer in layer_array:
layer.learn(alpha)
# Gather data for the plots
sample_error_array.append(sample_error)
# print("{}.{} Error = {:.5f}".format(iter, sample_index, sample_error))
Learning is done from bottom to top, using the deltas stored in the output layer. These are backpropagated through the layers, and the changes in the weights are scaled to 20% of the calculated values so we settle nicely.
We also gather the error data (for each streetlight-walk/stop sample) into a matrix that we can print out when we’re done. If we want to, we can print the error for each sample in the training. Some converge faster than others, but this is not the best way to see that.
error /= num_samples
if (iter % 10) == 0 :
print("{} Error = {:.5f}".format(iter, error))
iter += 1
# stop even if we don't converge
if iter > max_iter:
break
At the bottom of the loop, we calculate the average error over all the samples. We then see if we’ve been here too long and break if we are, regardless of whether we’ve converged or not. And lastly, this is how I like to print formatted strings in Python (essentially the same as “%.5f” in Java/C/etc).
Once the loop terminates, we need to see how well the network has learned. As I said earlier, in a real machine learning situation we would be careful about issues such as overfitting by, for example, training against one set of data and testing against another. But since this is a toy problem, so we are simply going to see how it did with the training data. I’ve added some explicit variables for clarity:
- prediction: The contents of the single neuron in the output layer
- observed: The value in the walk/stop array that we’re evaluating against
- accuracy: how close did we get?
print("\n--------------evaluation")
for sample_index in range(len(streetlights_array)):
input.set_neurons(streetlights_array[sample_index])
for layer in reversed(layer_array):
layer.train()
prediction = float(output.neuron_row_array)
observed = float(walk_vs_stop_array[sample_index])
accuracy = 1.0 - abs(prediction - observed)
print("sample {} - input: {} = pred: {:.3f} vs. actual:{} ({:.2f}% accuracy)".
format(sample_index, input.neuron_row_array, prediction, observed, accuracy*100.0))
Since the network is already set up with weights, all we need to do is to see how well our inputs match to our outputs. All this means is to take a set of inputs and run them forward to the model. There will be no learning via backpropagation.
So let’s see how we did!
0 Error = 0.35238 10 Error = 0.29001 20 Error = 0.19074 30 Error = 0.12883 40 Error = 0.04666 50 Error = 0.00544 --------------evaluation sample 0 - input: [[1. 0. 1.]] = pred: 0.978 vs. actual:1.0 (97.78% accuracy) sample 1 - input: [[0. 1. 1.]] = pred: 1.000 vs. actual:1.0 (100.00% accuracy) sample 2 - input: [[0. 0. 1.]] = pred: 0.037 vs. actual:0.0 (96.27% accuracy) sample 3 - input: [[1. 1. 1.]] = pred: 0.000 vs. actual:0.0 (99.95% accuracy)
As you can see, the values converge in less than 60 iterations, and the predictions are quite close. For the second and fourth stoplight pattern, the results are basically exact (100% and 99.95%). That’s not bad for a bunch of random numbers and two simple rules.
These are the kinds of outputs that you get with heavyweight packages like Keras. It’s helpful (We trained successfully! Horay!). And these types of outputs make sense when models are huge – or even bigger toy problems like MNIST (which we will explore in a future post).
But this is toy code for a toy problem so we can show more than that. Being able to visualize what’s going on is very helpful. That’s why the error for each step has been saved in error_plot_mat.
Plotting data like this in Python is one of the joys of using the language. Here’s what it takes:
# plots ----------------------------------------------
fig_num = 1
f1 = plt.figure(fig_num)
plt.plot(error_plot_mat)
plt.title("error")
names = []
for i in range(num_samples):
names.append("sample_{}".format(i))
names.append("average")
plt.legend(names)
for layer in reversed(layer_array):
if layer.target != None:
fig_num += 1
layer.plot_weight_matrix(var_name='sample_{}'.format(fig_num),fig_num=fig_num)
for layer in reversed(layer_array):
fig_num += 1
layer.plot_neuron_matrix(fig_num)
plt.show()
We are going to be creating a bunch of plots. One for the error, and then one for each set of neurons and their weights. We’ll get back to the layer plots when we’re walking through SimpleLayer, but here’s a plot of all the errors, by sample and average for the entire training session:
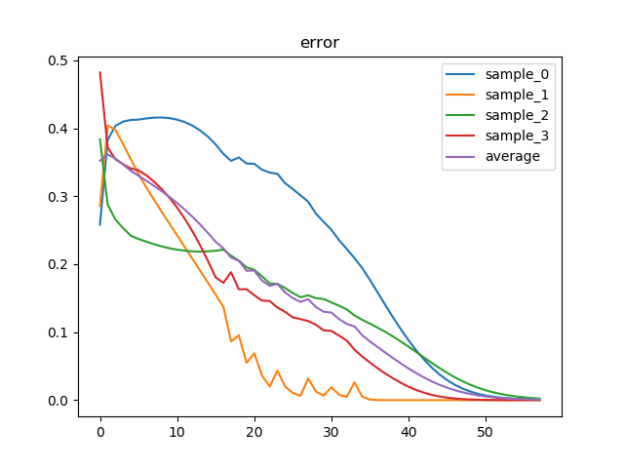
Figure 4: Error for each sample
Some things worth noting are this is not a linear process. There are times where the learning process is pretty slow, particularly at the beginning in this example. The second observation is that zero error happens much sooner for some samples than others. The first sample with zero error happens around step 150 (iteration 37 or so of the main loop). If the exit condition were based on looking at one sample instead of the average of all the sample errors, the system could exit early. I had this happen when I was using sample_error rather than error in the exit condition. It took a while to figure out why some seed values behaved so differently from others….
And that ends the tour of the main loop. Next, we’ll look at how a layers interact to train and learn.
SimpleLayer
The previous section is roughly equivalent to a Keras, Torch, or other machine learning framework. You get an idea of the behavior of a system and how the construction affects the output, but the details of the implementation are hidden. In this section, we’re going to look at the creation of a layer in detail – the ways they are connected and the ways that they communicate. As with the walkthrough of the main loop, we’ll start with the construction of the layer, then the forward learning process, the training backpropagation process, and graph what’s going on.
Construction
As with simple_nn.py, SimpleLayer is written to have very few dependencies. I actually struggled with whether or not to write my own matrix math, but I think NumPy is pretty clear, and it would get distracting with all the additional code.
import numpy as np import matplotlib.pyplot as plt import types import typing
There are some class-wide variables that we should describe:
class SimpleLayer:
name = "unset"
neuron_row_array = None
neuron_col_array = None
weight_row_mat = None
weight_col_mat = None
plot_mat = [] # for drawing plots
num_neurons = 0
delta = 0 # the 'movement' scalar
target = None
source = None
activation_func = None
derivative_func = None
In order of declaration, these are
- name: the string name of the layer. Used in printing and surprisingly useful in debugging
- neuron_row_array: the neurons in row form (i.e. [[n1, n2, n3, … , nN])
- neuron_col_array: the transpose of neuron_row_array (i.e. [[n1], [n2], [n3], … ,[nN]]. We need the data in both forms for interactions between layers
- weight_row_mat: the weights in row format, as above
- weight_col_mat: the weights in column format, as above
- weight_history_mat: where the weight data from each training pass is stored for plotting
- neuron_history_mat: where the neuron data from each training pass is stored for plotting
- num_neurons: the number of neurons in this layer
- delta: the scalar that changes the size of the “step” this layer takes as it tries to converge on the goal. Passed in as alpha in simple_nn.py
- target: the layer “below” this layer. May be NULL
- source: the layer “above” this layer. May be NULL
- activation_func: the function that controls the nonlinearity of the training process. Passed in as relu() from simple_nn
- derivative_func: the function used in backpropagation that is the derivative of the activation function. Passed in as relu2deriv() in simple_nn
Next is the initialization, which is done through the constructor:
# set up the layer with the number of neurons, the next layer in the sequence, and the activation/backprop functions
def __init__(self, name, num_neurons: int, activation_ptr: types.FunctionType, deriv_ptr: types.FunctionType, target: 'SimpleLayer' = None):
self.reset()
self.activation_func = activation_ptr
self.derivative_func = deriv_ptr
self.name = name
self.num_neurons = num_neurons
self.neuron_row_array = np.zeros((1, num_neurons))
self.neuron_col_array = np.zeros((num_neurons, 1))
# We only have weights if there is another layer below us
for i in range(num_neurons):
self.neuron_history_mat.append([])
if(target != None):
self.target = target
target.source = self
self.weight_row_mat = 2 * np.random.random((num_neurons, target.num_neurons)) - 1
self.weight_col_mat = self.weight_row_mat.T
This takes the values supplied in the create_layer() method in simple_nn.py and bulds the layer. Once the local variables are set, the matricies of neurons are created.
If there is a target, the two layers are connected. What this means is that the source layer creates a numpy matrix that has as many rows as the source neurons and as many columns as the target neurons (See figure 3). This matrix is the weights that are used to uniquely distribute the value of each neuron in the source layer to each neuron in the target layer. As with the neurons, this is stored in row and column form.
Once each layer is set up, we are ready to begin the training process.
Training
Training a neural network is the process of take a set of input values and sending them through the entire network to get an output. We can compare that output to the desired value, and then adjust. Using the mechanism of a deep neural network allows us to build a system that can map many input values to a desired output value. In this case, we’re looking at three values in an array, but using exactly the same structure, we can increase the number of values to be the pixels in an image and the output to be the label for that image:

Figure 5: The CFAR-10 Dataset
That takes more layers and some other tricks, but the basic technique is the same.
Ok, back to three values in an array that represent some streetlights. To get this into the input layer, we use the set_neurons() method:
# Fill neurons with values
def set_neurons(self, val_list: typing.List):
# print("cur = {}, input = {}".format(self.neuron_array, val_list))
for i in range(0, len(val_list)):
self.neuron_row_array[0][i] = val_list[i]
self.neuron_col_array = self.neuron_row_array.T
The numpy neuron arrays are actually two-dimensional arrays that are one element deep. This supports numpy array math like dot product and transpose. That’s why the awkward syntax where we take the val_list and set the neurons to those values. We then take the transpose immediately so that I don’t have to wonder if it’s been done already.
The next step is to ripple the values through the network layers:
def train(self):
# if not the bottom layer, we can record values for plotting
if(self.target != None):
self.weight_history_mat.append(self.nparray_to_list(self.weight_row_mat))
# if we're not the top layer, propagate weights
if self.source != None:
src = self.source
# set our neuron values as the dot product of the source neurons, and the source weights
self.neuron_row_array = np.dot(src.neuron_row_array, src.weight_row_mat)
# No activation function to output layer
if(self.target != None):
# Adjust the values based on the activation function. This introduces nonlinearity.
# For example, the relu function clamps all negative values to zero
self.neuron_row_array = self.activation_func(self.neuron_row_array)
# Transpose the neuron array and save for learn()
self.neuron_col_array = self.neuron_row_array.T
# record values for plotting
for i in range(self.num_neurons):
self.neuron_history_mat[i].append(self.neuron_row_array[0][i])
We start to see how intimately the layers are connected in this method. We look to the target and source layers to adjust our behaviors and set values.
Since this is the top layer, we have no source. That means that record our weights for later plotting and we’re done. The layer below us will set its neurons based this layer’s weights and neurons, as handled in this line:
self.neuron_row_array = np.dot(src.neuron_row_array, src.weight_row_mat)
This is just the first step. If we’re not the bottom layer, we have to see if the neuron values make it past the activation function that we set in simple_nn.py:
# activation function: sets all negative numbers to zero
# Otherwise returns x
def relu(x: np.array) -> np.array :
return (x > 0) * x
This is done with these lines:
# No activation function to output layer
if(self.target != None):
# Adjust the values based on the activation function. This introduces nonlinearity.
# For example, the relu function clamps all negative values to zero
self.neuron_row_array = self.activation_func(self.neuron_row_array)
By running these same methods on each successive layer object, the streetlight values are slowly, and nonlinearly (in multi-layer networks, which is critical) modified to produce a single output. Unfortunately, that output is guaranteed to be wrong, since it’s based on multiplying the input values by a bunch of random values that we set up each layer with.
Time to fix that.
Learning
Back in simple_nn.py, between the train() and the learn() loops is this line:
delta = output.calc_delta(walk_vs_stop_array[sample_index])
The delta saves out the error for the plotting. The function sets up the values for the learning step:
def calc_delta(self, goal: np.array) -> float:
self.delta = goal - self.neuron_row_array
return self.delta
self.delta is a numpy array that stores the difference between the goal(s) and the current value. In this case, there is only one value, but this also works with multiple values. That’s another trick that gets used in training networks. For example, in handling the CIFAR images, there is an output neuron for each category (e.g. horse, automobile, truck, ship, etc.). In out toy example and in the CIFAR case, the goal is a one or zero in the output neuron(s). The delta is the difference between the computed value and the goal. That delta is what we will now backpropagate through the layers, from back to front. And that’s the learning process.
In learning, the basic goal is to adjust the weights that set this layer’s neurons (in this implementation, the source layer). This is done by backpropagating the error delta from this layer to the source layer. Since we only want to adjust the weights that participated in the training, we need to take the derivative of the activation function in train(). Again, the weight matrix is simply the source neurons times this layer’s neurons. For example, if the source layer had three neurons and this layer had four, then the (source) weight matrix would be 3*4 = 12 weights. The whole method is shown below.
def learn(self, alpha):
if self.source != None:
src = self.source
delta_scalar = np.dot(self.delta, src.weight_col_mat)
delta_threshold = self.derivative_func(src.neuron_row_array)
src.delta = delta_scalar * delta_threshold
mat = np.dot(src.neuron_col_array, self.delta)
src.weight_row_mat += alpha * mat
src.weight_col_mat = src.weight_row_mat.T
There’s a lot going on here, so let’s go through it slowly:
def learn(self, alpha):
# if there is a layer above us
if self.source != None:
src = self.source
Since weights exist between neurons, we once more have the intimate relationship between this layer’s neurons and the layer above this layer. If there is no layer above us, there is literally nothing to do, which is why this test is first.
delta_scalar = np.dot(self.delta, src.weight_col_mat)
Next, we calculate the error delta scalar array, which is the amount the source layer needs to change (set initially in the output layer’s calc_delta(), then rippled up through the layers), multiplied across the weights used to set this layer’s neurons (in the source).
delta_threshold = self.derivative_func(src.neuron_row_array)
In the train() process, we distributed the values in a non-linear way – any neuron value below zero was not distributed. (the relu() function from simple_nn.py). That process needs to be mirrored in the backpropagation process. There is always a matched pair of methods that make the core of a neural network – the activation function, and the derivative function.
src.delta = delta_scalar * delta_threshold
This is where the actual change for the source layer is calculated. It’s the product of the delta_scalar and the delta_threshold that we’ve just calculated. This is where the decision process of the derivitive_func() is scaled to the desired amount (the alpha value that we pass in from simple_nn.py). This value will be used when the learn() method is called for the source layer. Like I said, layers are intimately connected.
We now take the self.delta that was calculated in our target layer’s learn() method, and use it to adjust the weights in the source layer that will be used to set our neuron’s values on the next train() pass.
mat = np.dot(src.neuron_col_array, self.delta) src.weight_row_mat += alpha * mat src.weight_col_mat = src.weight_row_mat.T
This matrix (mat) contains the adjustments for the source layer’s weights. We want to add a fraction of these (or we won’t converge) values, so we multiply by alpha. The last step is simply making the transpose of the weight matrix.
And that’s pretty much the guts of this implementation. The important things to remember are:
- Input and output layers are special cases. The neurons are explicitly set in the input layer and there is no activation or derivative function applied to the output neurons (no, I don’t know why yet. When I figure that out, I’ll explain why here)
- In training, the current layer’s neuron’s values are set by multiplying the source neurons by the source weights.
- In learning, the source layer’s weights are adjusted by the current layer’s deltas, but thresholded by the derivative of the source layer’s neurons
This is pretty complicated, and I’ve split out the steps so that it’s possible to step through the running code in the debugger and see what’s going on with the values. But that only gives a level of insight at a single step. how can we show the global behavior of a layer?
Graphing
We are going to graph both the changing value of the neurons and the evolving weights. The neurons are an easier problem so we’ll start there:
def plot_neuron_matrix(self, fig_num: int):
title = "{} neuron history".format(self.name)
plt.figure(fig_num)
np_mat = np.array(self.neuron_history_mat)
plt.plot(np_mat.T, '-o', linestyle=' ', ms=2)
names = []
for i in range(self.num_neurons):
names.append("neuron {}".format(i))
plt.legend(names)
plt.title(title)
This method simply takes the history matrix (where we had a column for each time sample), turns it into a numpy array for easier manipulation and plotting, and plots the transpose (where each neuron’s history is a row). Because the neuron’s values change for each sample, the history of how they converge towards the final values doesn’t show up well with lines, so I set the drawing arguments to points ‘-o’, no line ‘ ‘ , with a point size of 2 pixels (ms=2):


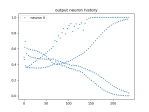
Figure 6: Neuron Histories by layer (click to embiggen)
In the input layer, we see that the neurons are either one or zero, just as we set them. These values are then multiplied by the (initially random) weights and further adjusted by the activation function. Those values ripple through the hidden layer, where they are initially random overthe (0, 1) interval where they are then used to adjust the output neurons (which does not involve an activation function). Over time, you can see the system settle into a state where all neurons are either one or zero, depending on the inputs. So how do the weights achieve this?
Even in this toy system, there are still a lot of weights to keep track of, and I’m still working on a way of visualizing the process. I’m visualizing the weights instead of the neurons, because the weights are the “factors in the equation” that manipulate the “x” values to get a “y”. On other words, I’m watching how the “m” and “b” converge on their values in “y = mx + b”, rather than looking at a particular “x” or “y”.
The method that does this is plot_weight_matrix(), which assembles a chart for each set of weights and is called at the end of simple_nn.py:
def plot_weight_matrix(self, fig_num: int):
var_name = "weight"
title = "{} to {} {}".format(self.name, self.target.name, var_name)
plt.figure(fig_num)
np_mat = np.array(self.weight_history_mat)
i = 0
for row in np_mat.T:
cstr = "C{}".format(i % self.num_neurons)
plt.plot(row, linewidth = int(i / self.num_neurons)+1, color=cstr)
i += 1
names = []
num_weights = self.num_neurons * self.target.num_neurons
for i in range(num_weights):
src_n = i % self.num_neurons
targ_n = int(i/self.num_neurons)
names.append("{} s:t[{}:{}]".format(var_name, src_n, targ_n))
plt.legend(names)
plt.title(title)
One of the reasons that I really like OO programming is that so much useful data is associated with the object. You don’t have to go looking for it, or scope things in peculiar ways. As a result, for example, generating the title is simply assembling some strings that I already have lying around.
title = "{} to {} {}".format(self.name, self.target.name, var_name)
The next important step is to get the data that we’ve been assembling in train() into a form that the plotting library likes. The data has been assembled in an list of lists, where each individual list is a snapshot of the weights at one step in the training process. I do it this way because of two reasons:
- I don’t know how many steps this process is going to take, and python lists handle dynamic memory allocation nicely.
- The weight matrix is a 2D NumPy array, and dealing with a series of matricies is something that PyPlot has no idea how to handle.
Here’s the line from train():
if(self.target != None):
self.plot_mat.append(self.nparray_to_list(self.weight_row_mat))
PyPlot doesn’t really like to handle lists of lists, but it does know how to handle one big NumPy array, so we convert the list of lists to a matrix where the rows are the weights, and the columns are the timesteps:
np_mat = np.array(self.plot_mat)
At this point we could simply plot everything:
plt.plot(np_mat)
That produces a pretty chart:

Figure 7: First pass at drawing a lot of weights
But it’s pretty confusing. There are a lot of lines. So I did two related things. I set line thickness to be a function of which target neuron and the color of the line to be a function of which source neuron. Using the same scheme, I built the a legend to indicate the source and target neurons that identify each weight, using the coordinates of the matrix – basically treating it as an adjacency matrix.
i = 0
for row in np_mat.T:
cstr = "C{}".format(i % self.num_neurons)
plt.plot(row, linewidth = int(i / self.num_neurons)+1, color=cstr)
i += 1
names = []
num_weights = self.num_neurons * self.target.num_neurons
for i in range(num_weights):
src_n = i % self.num_neurons
targ_n = int(i/self.num_neurons)
names.append("{} s:t[{}:{}]".format(var_name, src_n, targ_n))
plt.legend(names)
plt.title(title)
And that gives a chart that lets us examine what’s going on. All the blue lines are the weights that adjust the value coming from source neuron one, distributed over target neurons [0, 1, 2, 3]. All the thin lines are all the weights that set the value of target neuron one from source neurons [0, 1, 2]:

Figure 8: Weights between input and hidden layers
We now have a way to visualize the whole process inside the layers. Let’s see if we can learn anything by looking at how the neurons and weights coevolve over time.
Some final thoughts
I think the fundamental lesson here is one of gradient descent (or hill climbing if you prefer) from a random initial state to a stable set of values that will set the variables in a function. Once those values are found, the function can do it’s job, which in this case is taking a set of observations – ([ 1, 0, 1 ], [ 0, 1, 1 ], [ 0, 0, 1 ], [ 1, 1, 1 ]) and transforming them to a different set of values – ([1], [1], [0], [0]).




Figure 9: Weights influencing neurons
This is at its core stochastic, a mechanism for harnessing randomness by using rules. The weights and neurons exist in a constrained, multidimensional space. Much of this is fixed before a single iteration – the number of neurons and how they are arranged. The types of connections (activation and derivative functions). The initial value of the weights. Even the manner of input and the “fitness test” that determines the error that is measured. Within these constraints, the weights move slowly under multiple influences until they settle into places that they are no longer forced to move. That’s it.
Variations in this system can be used for all kinds of things, ranging from image recognition to generating words, but the basic process is always the same.
I hope this helped you to read as much it helped me to write!
Full code listings
For the most current versions, please use the GitHub repo, but these are up to date as of January 10, 2019
simple_nn.py
'''
Copyright 2019 Philip Feldman
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
associated documentation files (the "Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial
portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT
LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO
EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR
THE USE OR OTHER DEALINGS IN THE SOFTWARE.
'''
# based on https://github.com/iamtrask/Grokking-Deep-Learning/blob/master/Chapter6%20-%20Intro%20to%20Backpropagation%20-%20Building%20Your%20First%20DEEP%20Neural%20Network.ipynb
import numpy as np
import matplotlib.pyplot as plt
import src.SimpleLayer as sl
# Methods ---------------------------------------------
# activation function: sets all negative numbers to zero
# Otherwise returns x
def relu(x: np.array) -> np.array :
return (x > 0) * x
# This is the derivative of the above relu function, since the derivative of 1x is 1
def relu2deriv(output: np.array) -> np.array:
return 1.0*(output > 0) # returns 1 for input > 0
# return 0 otherwise
# create a layer
def create_layer(layer_name: str, neuron_count: int, target: sl.SimpleLayer = None) -> 'SimpleLayer':
layer = sl.SimpleLayer(layer_name, neuron_count, relu, relu2deriv, target)
layer_array.append(layer)
return layer
# variables ------------------------------------------
np.random.seed(0)
alpha = 0.2
# the samples. Columns are the things we're sampling, rows are the samples
streetlights_array = np.array( [[ 1, 0, 1 ],
[ 0, 1, 1 ],
[ 0, 0, 1 ],
[ 1, 1, 1 ]])
num_streetlights = len(streetlights_array[0])
num_samples = len(streetlights_array)
# The data set we want to map to. Each entry in the array matches the corresponding streetlights_array row
walk_vs_stop_array = np.array([[1],
[1],
[0],
[0]])
# set up the dictionary that will store the numpy weight matrices
layer_array = []
error_plot_mat = [] # for drawing plots
#set up the layers from last to first, so that there is a target layer
output = create_layer("output", 1)
output.set_neurons([1])
''' # If we want to have four layers (two hidden), use this and comment out the other hidden code below
hidden2 = create_layer("hidden2", 2, output)
hidden2.set_neurons([1, 2])
hidden = create_layer("hidden", 4, hidden2)
hidden.set_neurons([1, 2, 3, 4])
'''
# If we want to have three layers (one hidden), use this and comment out the other hidden code above
hidden = create_layer("hidden", 4, output)
hidden.set_neurons([1, 2, 3, 4])
input = create_layer("input", 3, hidden)
input.set_neurons([1, 2, 3])
for layer in reversed(layer_array):
print ("--------------")
print (layer.to_string())
iter = 0
max_iter = 1000
epsilon = 0.001
error = 2 * epsilon
while error > epsilon:
error = 0
sample_error_array = []
for sample_index in range(num_samples):
input.set_neurons(streetlights_array[sample_index])
for layer in reversed(layer_array):
layer.train()
delta = output.calc_delta(walk_vs_stop_array[sample_index])
sample_error = np.sum(delta ** 2)
error += sample_error
for layer in layer_array:
layer.learn(alpha)
# Gather data for the plots
sample_error_array.append(sample_error)
# print("{}.{} Error = {:.5f}".format(iter, sample_index, sample_error))
error /= num_samples
sample_error_array.append(error)
error_plot_mat.append(sample_error_array)
if (iter % 10) == 0 :
print("{} Error = {:.5f}".format(iter, error))
iter += 1
# stop even if we don't converge
if iter > max_iter:
break
print("\n--------------evaluation")
for sample_index in range(len(streetlights_array)):
input.set_neurons(streetlights_array[sample_index])
for layer in reversed(layer_array):
layer.train()
prediction = float(output.neuron_row_array)
observed = float(walk_vs_stop_array[sample_index])
accuracy = 1.0 - abs(prediction - observed)
print("sample {} - input: {} = pred: {:.3f} vs. actual:{} ({:.2f}% accuracy)".
format(sample_index, input.neuron_row_array, prediction, observed, accuracy*100.0))
# plots ----------------------------------------------
fig_num = 1
f1 = plt.figure(fig_num)
plt.plot(error_plot_mat)
plt.title("error")
names = []
for i in range(num_samples):
names.append("sample_{}".format(i))
names.append("average")
plt.legend(names)
for layer in reversed(layer_array):
if layer.target != None:
fig_num += 1
layer.plot_weight_matrix(fig_num)
for layer in reversed(layer_array):
fig_num += 1
layer.plot_neuron_matrix(fig_num)
plt.show()
SimpleLayer.py
'''
Copyright 2019 Philip Feldman
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
associated documentation files (the "Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial
portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT
LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO
EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR
THE USE OR OTHER DEALINGS IN THE SOFTWARE.
'''
# based on https://github.com/iamtrask/Grokking-Deep-Learning/blob/master/Chapter6%20-%20Intro%20to%20Backpropagation%20-%20Building%20Your%20First%20DEEP%20Neural%20Network.ipynb
import numpy as np
import matplotlib.pyplot as plt
import types
import typing
# methods --------------------------------------------
class SimpleLayer:
name = "unset"
neuron_row_array = None
neuron_col_array = None
weight_row_mat = None
weight_col_mat = None
weight_history_mat = [] # for drawing plots
neuron_history_mat = []
num_neurons = 0
delta = 0 # the amount to move the source layer
target = None
source = None
activation_func = None
derivative_func = None
# set up the layer with the number of neurons, the next layer in the sequence, and the activation/backprop functions
def __init__(self, name, num_neurons: int, activation_ptr: types.FunctionType, deriv_ptr: types.FunctionType, target: 'SimpleLayer' = None):
self.reset()
self.activation_func = activation_ptr
self.derivative_func = deriv_ptr
self.name = name
self.num_neurons = num_neurons
self.neuron_row_array = np.zeros((1, num_neurons))
self.neuron_col_array = np.zeros((num_neurons, 1))
# We only have weights if there is another layer below us
for i in range(num_neurons):
self.neuron_history_mat.append([])
if(target != None):
self.target = target
target.source = self
self.weight_row_mat = 2 * np.random.random((num_neurons, target.num_neurons)) - 1
self.weight_col_mat = self.weight_row_mat.T
def reset(self):
self.name = "unset"
self.target = None
self.neuron_row_array = None
self.neuron_col_array = None
self.weight_row_mat = None
self.weight_col_mat = None
self.weight_history_mat = [] # for drawing plots
self. neuron_history_mat = []
self.num_neurons = 0
self.delta = 0 # the amount to move the source layer
self.target = None
self.source = None
# Fill neurons with values
def set_neurons(self, val_list: typing.List):
# print("cur = {}, input = {}".format(self.neuron_array, val_list))
for i in range(0, len(val_list)):
self.neuron_row_array[0][i] = val_list[i]
self.neuron_col_array = self.neuron_row_array.T
def get_plot_mat(self) -> typing.List:
return self.weight_history_mat
# In training, the basic goal is to set a value for the layer's neurons, based on the weights in the source layer mediated by an activation function.
# This matrix is simply the source neurons times this layer's neurons. For example, if the source layer had three neurons and this layer had four, then
# the (source) weight matrix would be 3*4 = 12 weights.
def train(self):
# if not the bottom layer, we can record values for plotting
if(self.target != None):
self.weight_history_mat.append(self.nparray_to_list(self.weight_row_mat))
# if we're not the top layer, propagate weights
if self.source != None:
src = self.source
# set our neuron values as the dot product of the source neurons, and the source weights
self.neuron_row_array = np.dot(src.neuron_row_array, src.weight_row_mat)
# No activation function to output layer
if(self.target != None):
# Adjust the values based on the activation function. This introduces nonlinearity.
# For example, the relu function clamps all negative values to zero
self.neuron_row_array = self.activation_func(self.neuron_row_array)
# Transpose the neuron array and save for learn()
self.neuron_col_array = self.neuron_row_array.T
# record values for plotting
for i in range(self.num_neurons):
self.neuron_history_mat[i].append(self.neuron_row_array[0][i])
# In learning, the basic goal is to adjust the weights that set this layer's neurons (in this implementation, the source layer). This is done
# by backpropagating the error delta from this layer to the source layer. Since we only want to adjust the weights that participated in the
# training, we need to take the derivative of the activation function in train(). Again, the weight matrix is simply the source neurons times
# this layer's neurons. For example, if the source layer had three neurons and this layer had four, then the (source) weight matrix would be 3*4 = 12 weights.
def learn(self, alpha):
# if there is a layer above us
if self.source != None:
src = self.source
# calculate the error delta scalar array, which is the amount this layer needs to change,
# multiplied across the weights used to set this layer (in the source)
delta_scalar = np.dot(self.delta, src.weight_col_mat)
# determine the backpropagation distribution. In the case of Relu, it's just one or zero
delta_threshold = self.derivative_func(src.neuron_row_array)
# set the amount the source layer needs to change, based on this layer's delta distributed over the source
# neurons
src.delta = delta_scalar * delta_threshold
# create the weight adjustment matrix by taking the dot product of the source layer's neurons (as columns) and the
# scaled, thresholded row of deltas based on this layer's error delta and the source's weight layer
mat = np.dot(src.neuron_col_array, self.delta)
# add some percentage of the weight adjustment matrix to the source weight matrix
src.weight_row_mat += alpha * mat
src.weight_col_mat = src.weight_row_mat.T
# given one or more goals (that match the number of neurons in this layer), determine the delta that, when added to the
# neurons, would reach that goal
def calc_delta(self, goal: np.array) -> float:
self.delta = goal - self.neuron_row_array
return self.delta
# helper function to turn a NumPy array to a Python list
def nparray_to_list(self, vals: np.array) -> typing.List[float]:
data = []
for x in np.nditer(vals):
data.append(float(x))
return data
def to_string(self):
target_name = "no target"
source_name = "no source"
if self.target != None:
target_name = self.target.name
if self.source != None:
source_name = self.source.name
return "layer {}: \ntarget = {}\nsource = {}\nneurons (row) = {}\nweights (row) = \n{}".format(self.name, target_name, source_name, self.neuron_row_array, self.weight_row_mat)
# create a line chart of the plot matrix that we've been building
def plot_weight_matrix(self, fig_num: int):
var_name = "weight"
title = "{} to {} {}".format(self.name, self.target.name, var_name)
plt.figure(fig_num)
np_mat = np.array(self.weight_history_mat)
i = 0
for row in np_mat.T:
cstr = "C{}".format(i % self.num_neurons)
plt.plot(row, linewidth = int(i / self.num_neurons)+1, color=cstr)
i += 1
names = []
num_weights = self.num_neurons * self.target.num_neurons
for i in range(num_weights):
src_n = i % self.num_neurons
targ_n = int(i/self.num_neurons)
names.append("{} s:t[{}:{}]".format(var_name, src_n, targ_n))
plt.legend(names)
plt.title(title)
def plot_neuron_matrix(self, fig_num: int):
title = "{} neuron history".format(self.name)
plt.figure(fig_num)
np_mat = np.array(self.neuron_history_mat)
plt.plot(np_mat.T, '-o', linestyle=' ', ms=2)
names = []
for i in range(self.num_neurons):
names.append("neuron {}".format(i))
plt.legend(names)
plt.title(title)
