
Characterizing Online Public Discussions through Patterns of Participant Interactions
Authors
- Justine Zhang (Scholar) (Github)
- Cristian Danescu-Niculescu-Mizil (Scholar)
- Christina Sauper
- Sean J. Taylor (Scholar)
Overview
An important paper that lays out mechanisms for relating conversations into navigable spaces. To me, this seems like a first step in being able to map human interaction along the dimensions the humans emphasize. In this case, the dimensions have to do with relatively coarse behavior trajectories: Will a participant block another? Will this be a long threaded discussion among a few people or a set of short links all referring to an initial post?
Rooted in the design affordances of facebook, the data that are readily available influence the overall design of the methods used. For example, a significant amount of the work is focussed on temporal network analytics. I think that these methods are quite generalizable to sites like Twitter and Reddit. The fact that the researchers worked at Facebook and had easy access to the data is a critical part of this studies’ success. For me the implications aren’t that surprising (I found myself saying “Yes! Yes!” several times while reading this), but it is wonderful to see then presented in such a clear, defensible way.
My more theoretical thoughts
Though this study is focussed more on building representations of behaviors, I think that the methods used here (particularly as expanded on in the Future Work section) should be extensible to mapping beliefs.
The extensive discussion about how the design affordances of Facebook create the form of the discussion is also quite validating. Although they don’t mention it, Moscovici lays this concept out in Conflict and Consensus, where he describes how even items such as table shape can change a conversation so that the probability of compromise over consensus is increased.
Lastly, I’m really looking forward to checking out the Cornell Conversational Analysis Toolkit, developed for(?) this study.
Notes
- This paper introduces a computational framework to characterize public discussions, relying on a representation that captures a broad set of social patterns which emerge from the interactions between interlocutors, comments and audience reactions. (Page 198:1)
- we use it to predict the eventual trajectory of individual discussions, anticipating future antisocial actions (such as participants blocking each other) and forecasting a discussion’s growth (Page 198:1)
- platform maintainers may wish to identify salient properties of a discussion that signal particular outcomes such as sustained participation [9] or future antisocial actions [16], or that reflect particular dynamics such as controversy [24] or deliberation [29]. (Page 198:1)
- Systems supporting online public discussions have affordances that distinguish them from other forms of online communication. Anybody can start a new discussion in response to a piece of content, or join an existing discussion at any time and at any depth. Beyond textual replies, interactions can also occur via reactions such as likes or votes, engaging a much broader audience beyond the interlocutors actively writing comments. (Page 198:2)
- This is why JuryRoom would be distinctly different. It’s unique affordances should create unique, hopefully clearer results.
- This multivalent action space gives rise to salient patterns of interactional structure: they reflect important social attributes of a discussion, and define axes along which discussions vary in interpretable and consequential ways. (Page 198:2)
- Our approach is to construct a representation of discussion structure that explicitly captures the connections fostered among interlocutors, their comments and their reactions in a public discussion setting. We devise a computational method to extract a diverse range of salient interactional patterns from this representation—including but not limited to the ones explored in previous work—without the need to predefine them. We use this general framework to structure the variation of public discussions, and to address two consequential tasks predicting a discussion’s future trajectory: (a) a new task aiming to determine if a discussion will be followed by antisocial events, such as the participants blocking each other, and (b) an existing task aiming to forecast the growth of a discussion [9]. (Page 198:2)
- We find that the features our framework derives are more informative in forecasting future events in a discussion than those based on the discussion’s volume, on its reply structure and on the text of its comments (Page 198:2)
- we find that mainstream print media (e.g., The New York Times, The Guardian, Le Monde, La Repubblica) is separable from cable news channels (e.g., CNN, Fox News) and overtly partisan outlets (e.g., Breitbart, Sean Hannity, Robert Reich)on the sole basis of the structure of the discussions they trigger (Figure 4).(Page 198:2)

- These studies collectively suggest that across the broader online landscape, discussions take on multiple types and occupy a space parameterized by a diversity of axes—an intuition reinforced by the wide range of ways in which people engage with social media platforms such as Facebook [25]. With this in mind, our work considers the complementary objective of exploring and understanding the different types of discussions that arise in an online public space, without predefining the axes of variation. (Page 198:3)
- Many previous studies have sought to predict a discussion’s eventual volume of comments with features derived from their content and structure, as well as exogenous information [8, 9, 30, 69, inter alia]. (Page 198:3)
- Many such studies operate on the reply-tree structure induced by how successive comments reply to earlier ones in a discussion rooted in some initial content. Starting from the reply-tree view, these studies seek to identify and analyze salient features that parameterize discussions on platforms like Reddit and Twitter, including comment popularity [72], temporal novelty [39], root-bias [28], reply-depth [41, 50] and reciprocity [6]. Other work has taken a linear view of discussions as chronologically ordered comment sequences, examining properties such as the arrival sequence of successive commenters [9] or the extent to which commenters quote previous contributions [58]. The representation we introduce extends the reply-tree view of comment-to-comment. (Page 198:3)
- Our present approach focuses on representing a discussion on the basis of its structural rather than linguistic attributes; as such, we offer a coarser view of the actions taken by discussion participants that more broadly captures the nature of their contributions across contexts which potentially exhibit large linguistic variation.(Page 198:4)
- This representation extends previous computational approaches that model the relationships between individual comments, and more thoroughly accounts for aspects of the interaction that arise from the specific affordances offered in public discussion venues, such as the ability to react to content without commenting. Next, we develop a method to systematically derive features from this representation, hence producing an encoding of the discussion that reflects the interaction patterns encapsulated within the representation, and that can be used in further analyses.(Page 198:4)
- In this way, discussions are modelled as collections of comments that are connected by the replies occurring amongst them. Interpretable properties of the discussion can then be systematically derived by quantifying structural properties of the underlying graph: for instance, the indegree of a node signifies the propensity of a comment to draw replies. (Page 198:5)
- Quick responses that reflect a high degree of correlation would be tight. A long-delayed “like” could be slack?
- For instance, different interlocutors may exhibit varying levels of engagement or reciprocity. Activity could be skewed towards one particularly talkative participant or balanced across several equally-prolific contributors, as can the volume of responses each participant receives across the many comments they may author.(Page 198: 5)
- We model this actor-focused view of discussions with a graph-based representation that augments the reply-tree model with an additional superstructure. To aid our following explanation, we depict the representation of an example discussion thread in Figure 1 (Page 198: 6)
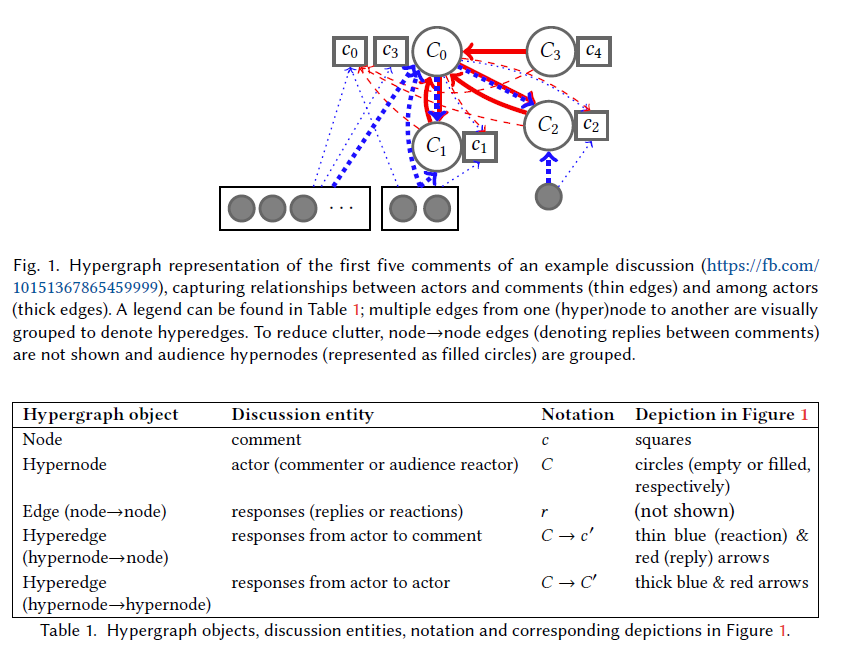
- Relationships between actors are modeled as the collection of individual responses they exchange. Our representation reflects this by organizing edges into hyperedges: a hyperedge between a hypernode C and a node c ‘ contains all responses an actor directed at a specific comment, while a hyperedge between two hypernodes C and C’ contains the responses that actor C directed at any comment made by C’ over the entire discussion. (Page 198: 6)
- I think that this can be represented as a tensor (hyperdimensional or flattened) with each node having a value if there is an intersection. There may be an overall scalar that allows each type of interaction to be adjusted as a whole
- The mixture of roles within one discussion varies across different discussions in intuitively meaningful ways. For instance, some discussions are skewed by one particularly active participant, while others may be balanced between two similarly-active participants who are perhaps equally invested in the discussion. We quantify these dynamics by taking several summary statistics of each in/outdegree distribution in the hypergraph representation, such as their maximum, mean and entropy, producing aggregate characterizations of these properties over an entire discussion. We list all statistics computed in the appendices (Table 4). (Page 198: 6, 7)

- To interpret the structure our model offers and address potentially correlated or spurious features, we can perform dimensionality reduction on the feature set our framework yields. In particular, let X be a N×k matrix whose N rows each correspond to a thread represented by k features.We perform a singular value decomposition on X to obtain a d-dimensional representation X ˜ Xˆ = USVT where rows of U are embeddings of threads in the induced latent space and rows of V represent the hypergraph-derived features. (Page 198: 9)
- This lets us find the hyperplane of the map we want to build
- Community-level embeddings. We can naturally extend our method to characterize online discussion communities—interchangeably, discussion venues—such as Facebook Pages. To this end, we aggregate representations of the collection of discussions taking place in a community, hence providing a representation of communities in terms of the discussions they foster. This higher level of aggregation lends further interpretability to the hypergraph features we derive. In particular, we define the embedding U¯C of a community C containing threads {t1, t2, . . . tn } as the average of the corresponding thread embeddings Ut1 ,Ut2 , . . .Utn , scaled to unit l2 norm. Two communities C1 and C2 that foster structurally similar discussions then have embeddings U¯C1 and U¯C2 that are close in the latent space.(Page 198: 9)
- And this may let us place small maps in a larger map. Not sure if the dimensions will line up though
- The set of threads to a post may be algorithmically re-ordered based on factors like quality [13]. However, subsequent replies within a thread are always listed chronologically.We address elements of such algorithmic ranking effects in our prediction tasks (§5). (Page 198: 10)
- Taken together, these filtering criteria yield a dataset of 929,041 discussion threads.(Page 198: 10)
- And approximately 9,290,410 posts. At an average of 18 words per post (Monitoring Trends on Facebook), that’s a corpora of 167,227,380 words
- We now apply our framework to forecast a discussion’s trajectory—can interactional patterns signal future thread growth or predict future antisocial actions? We address this question by using the features our method extracts from the 10-comment prefix to predict two sets of outcomes that occur temporally after this prefix. (Pg 198:10)
- These are behavioral trajectories, though not belief trajectories. Maps of these behaviors could probably be built, too.
- For instance, news articles on controversial issues may be especially susceptible to contentious discussions, but this should not translate to barring discussions about controversial topics outright. Additionally, in large-scale social media settings such as Facebook, the content spurring discussions can vary substantially across different sub-communities, motivating the need to seek adaptable indicators that do not hinge on content specific to a particular context. (Page 198: 11)
- Classification protocol. For each task, we train logistic regression classifiers that use our full set of hypergraph-derived features, grid-searching over hyperparameters with 5-fold cross-validation and enforcing that no Page spans multiple folds.13 We evaluate our models on a (completely fresh) heldout set of thread pairs drawn from the subsequent week of data (Nov. 8-14, 2017), addressing a model’s potential dependence on various evolving interface features that may have been deployed by Facebook during the time spanned by the training data. (Page 198: 11)
- We use logistic regression classifiers from scikit-learn with l2 loss, standardizing features and grid-searching over C = {0.001, 0.01, 1}. In the bag-of-words models, we tf-idf transform features, set a vocabulary size of 5,000 words and additionally grid-search over the maximum document frequency in {0.25, 0.5, 1}. (Page 198: 11, footnote 13)
- We test a model using the temporal rate of commenting, which was shown to be a much stronger signal of thread growth than the structural properties considered in prior work [9] (Page 198: 12)
- Table 3 shows Page-macroaveraged heldout accuracies for our prediction tasks. The feature set we extract from our hypergraph significantly outperforms all of the baselines in each task. This shows that interactional patterns occurring within a thread’s early activity can signal later events, and that our framework can extract socially and structurally-meaningful patterns that are informative beyond coarse counts of activity volume, the reply-tree alone and the order in which commenters contribute, along with a shallow representation of the linguistic content discussed. (Page 198: 12)
- So triangulation from a variety of data sources produces more accurate results in this context, and probably others. Not a surprising finding, but important to show
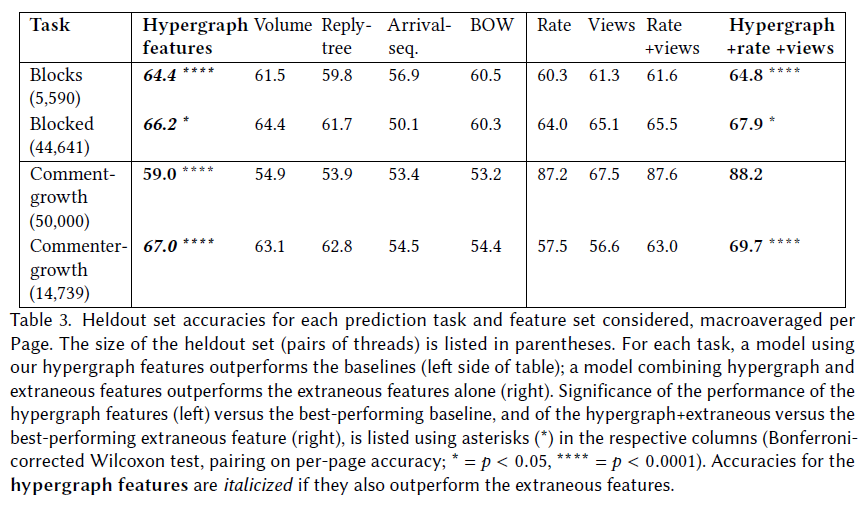
- We find that in almost all cases, our full model significantly outperforms each subcomponent considered, suggesting that different parts of the hypergraph framework add complementary information across these tasks. (Page 198: 13)
- Having shown that our approach can extract interaction patterns of practical importance from individual threads, we now apply our framework to explore the space of public discussions occurring on Facebook. In particular, we identify salient axes along which discussions vary by qualitatively examining the latent space induced from the embedding procedure described in §3, with d = 7 dimensions. Using our methodology, we recover intuitive types of discussions, which additionally reflect our priors about the venues which foster them. This analysis provides one possible view of the rich landscape of public discussions and shows that our thread representation can structure this diverse space of discussions in meaningful ways. This procedure could serve as a starting point for developing taxonomies of discussions that address the wealth of structural interaction patterns they contain, and could enrich characterizations of communities to systematically account for the types of discussions they foster. (Page 198: 14)
- ^^^Show this to Wayne!^^^
- The emergence of these groupings is especially striking since our framework considers just discussion structure without explicitly encoding for linguistic, topical or demographic data. In fact, the groupings produced often span multiple languages—the cluster of mainstream news sites at the top includes French (Le Monde), Italian (La Repubblica) and German (SPIEGEL ONLINE) outlets; the “sports” region includes French (L’EQUIPE) as well as English outlets. This suggests that different types of content and different discussion venues exhibit distinctive interactional signatures, beyond lexical traits. Indeed, an interesting avenue of future work could further study the relation between these factors and the structural patterns addressed in our approach, or augment our thread representation with additional contextual information. (Page 198: 15)
- Taken together, we can use the features, threads and Pages which are relatively salient in a dimension to characterize a type of discussion. (Page 198: 15)
- To underline this finer granularity, for each examined dimension we refer to example discussion threads drawn from a single Page, The New York Times(https://www.facebook.com/nytimes), which are listed in the footnotes. (Page 198: 15)
- Common starting point. Do they find consensus, or how the dimensions reduce?
- Focused threads tend to contain a small number of active participants replying to a large proportion of preceding comments; expansionary threads are characterized by many less-active participants concentrating their responses on a single comment, likely the initial one. We see that (somewhat counterintuitively) meme-sharing discussion venues tend to have relatively focused discussions. (Page 198: 15)
- These are two sides of the same dimension-reduction coin. A focused thread should be using the dimension-reduction tool of open discussion that requires the participants to agree on what they are discussing. As such it refines ideas and would produce more meme-compatible content. Expansive threads are dimension reducing to the initial post. The subsequent responses go in too many directions to become a discussion.
- Threads at one end (blue) have highly reciprocal dyadic relationships in which both reactions and replies are exchanged. Since reactions on Facebook are largely positive, this suggests an actively supportive dynamic between actors sharing a viewpoint, and tend to occur in lifestyle-themed content aggregation sub-communities as well as in highly partisan sites which may embody a cohesive ideology. In threads at the other end (red), later commenters tend to receive more reactions than the initiator and also contribute more responses. Inspecting representative threads suggests this bottom-heavy structure may signal a correctional dynamic where late arrivals who refute an unpopular initiator are comparatively well-received. (Page 198: 17)
- This contrast reflects an intuitive dichotomy of one- versus multi-sided discussions; interestingly, the imbalanced one-sided discussions tend to occur in relatively partisan venues, while multi-sided discussions often occur in sports sites (perhaps reflecting the diversity of teams endorsed in these sub-communities). (Page 198: 17)
- This means that we can identify one-sided behavior and use that then to look at they underlying information. No need to look in diverse areas, they are taking care of themselves. This is ecosystem management 101, where things like algae blooms and invasive species need to be recognized and then managed
- We now seek to contrast the relative salience of these factors after controlling for community: given a particular discussion venue, is the content or the commenter more responsible for the nature of the ensuing discussions? (Page 198: 17)
- This suggests that, perhaps somewhat surprisingly, the commenter is a stronger driver of discussion type. (Page 198: 18)
- I can see that. The initial commenter is kind of a gate-keeper to the discussion. A low-dimension, incendiary comment that is already aligned with one group (“lock her up”), will create one kind of discussion, while a high-dimensional, nuanced post will create another.
- We provide a preliminary example of how signals derived from discussion structure could be applied to forecast blocking actions, which are potential symptoms of low-quality interactions (Page 198: 18)
- The nature of the discussion may also be shaped by the structure of the underlying social network, such that interactions between friends proceed in contrasting ways from interactions between complete strangers. (Page 198: 19)
- Yep, design matters. Diversity injection matters.
- For instance, as with the bulk of other computational studies, our work relies heavily on indicators of interactional dynamics which are easily extracted from the data, such as replies or blocks. Such readily available indicators can at best only approximate the rich space of participant experiences, and serve as very coarse proxies for interactional processes such as breakdown or repair [27, 62]. As such, our implicit preference for computational expedience limits the granularity and nuance of our analyses. (Page 198: 20)
- Another argument for funding a platform that is designed to provide these nuances
- One possible means of enriching our model to address this limitation could be to treat nodes as high-dimensional vectors, such that subsequent responses only act on a subset of these dimensions. (Page 198: 21)
- Agreed. A set of matrices that represent an aspect of each node should have a rich set of capabilities
- Accounting for linguistic features of the replies within a discussion necessitates vastly enriching the response types presently considered, perhaps through a model that represents the corresponding edges as higher-dimensional vectors rather than as discrete types. Additionally, linguistic features might identify replies that address multiple preceding comments or a small subset of ideas within the target(s) of the reply, offering another route to move beyond the atomicity of comments assumed by our present framework. (Page 198: 21)
- Exactly right. High dimensional representations that can then be analyzed to uncover the implicit dimensions of interaction is the way to go, I think.
- Important references
- Cornell Conversational Analysis Toolkit
- This toolkit contains tools to extract conversational features and analyze social phenomena in conversations. Several large conversational datasets are included together with scripts exemplifying the use of the toolkit on these datasets.
- [5] Detecting Platform Effects in Online Discussions
- [6] To Thread or Not to Thread: The Impact of Conversation Threading on Online Discussion
- [8] Predicting responses to microblog posts.
- [9] Characterizing and curating conversation threads
- [12] Higher-order organization of complex networks
- [13] Discussion quality diffuses in the digital public square
- [16] Anyone can become a troll: Causes of trolling behavior in online discussions
- [24] Quantifying controversy in social media
- [28] Statistical analysis of the social network and discussion threads in Slashdot
- [29] The structure of political discussion networks: A model for the analysis of online deliberation
- [30] Exploring Text Virality in Social Networks
- [39] Dynamics of conversations
- [49] Conversational Markers of Constructive Discussions
- [50] Reply trees in Twitter: Data analysis and branching process models
- [58] Quotes Reveal Community Structure and Interaction Dynamics
- [69] Predicting the volume of comments on online news stories
- [72] From user comments to on-line conversations.
- [75] Democracy, deliberation and design: The case of online discussion forums
- Cornell Conversational Analysis Toolkit


{kind=link}