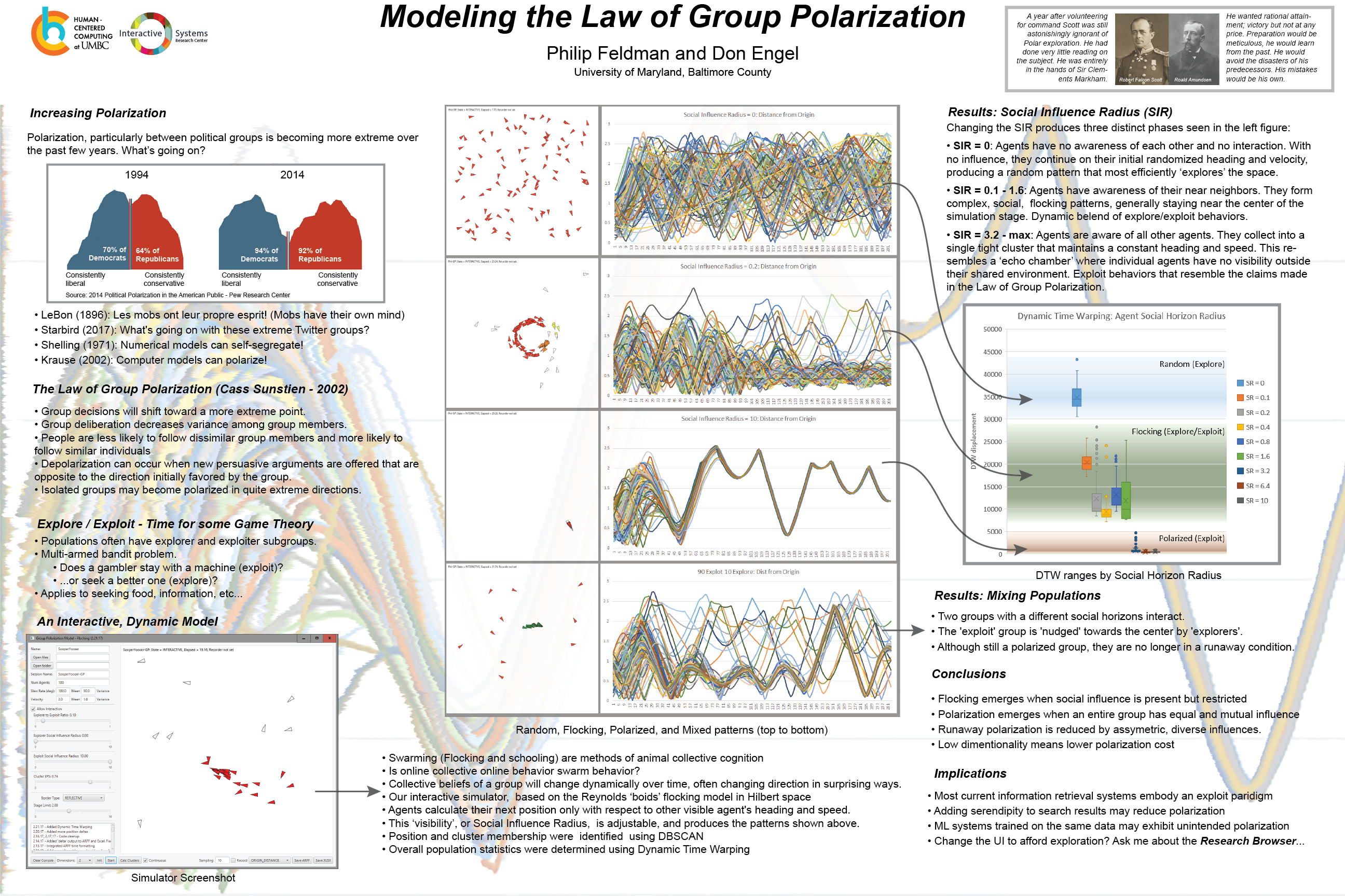
I’ve been using multilayer Perceptrons (MLPs) for some quickly trainable sequence-to-sequence time series predictions. The goal is to take sensor data from one day and use that as training data to predict the next day’s patterns. The application is extremely consistent, but the hardware slowly degrades. By retraining, the error detection system is able to “drift” with the system as various parts wear at different rates. And there are a lot of sensors – several thousand per system, so rapid training is a nice feature.
The problem that I was running into had to do with hyperparameter tuning. I would make a change or two, and then re-run the system on my well-characterized simulated data, and the accuracy of the result would change in odd ways. It was very frustrating.
As a way to work through more options in an automated way, I built an optimizer class using evolutionary algorithms (adjusting variables, rather than evolutionary programming, which evolves code). I could then fire up the evolver and try hundreds or thousands of models as the system worked to find the best fitness (in this case highest accuracy).
But there was a big problem, which I kind of knew about. The random initialization of weights makes a HUGE difference in the performance of the model. I discovered this while looking at the results of the evolver, which saves the best of each generation and saves them out to a spreadsheet:

If you look at row 8, you see a lovely fitness of 0.9, or 90%. Which was the best value from the evolver runs. However, after sorting on the parameters so that they were grouped, it became obvious that there is a HUGE variance in the results. The lowest fitness is 30%, and the average fitness for those values is actually 60%. I tried running the parameters on multiple trained models and got similar results. These values are all over the place. Not good.
To address this, I need to be able to run a population and get the distribution stats (mean, 5% and 95% confidence, min, and max outliers). I can then sort on the mean, but also have insight into the variance. A good mean with wide variance may be worse than a slightly worse mean with tight variance.
So I added statistical tests to the evolver, based on this post, starting with the scikit-learn resample(). Here’s the important bits:
def calc_fitness_stats(self, resample_size:int = 100):
boot = resample(self.population, replace=True, n_samples=resample_size, random_state=1)
s = pd.Series(boot)
conf = st.t.interval(0.95, len(boot)-1, loc=s.mean(), scale= st.sem(boot))
self.meta_info = {'mean':s.mean(), '5_conf':conf[0], '95_conf':conf[1], 'max':s.max(), 'min':s.min()}
self.fitness = s.mean()
To evaluate, I used my test landscape, a 3D surface, based on the equation z = cos(x) + sin(y) + (x + y)/10, over the range (-5, 5). I also added some randomness to the x and y values to noise up the results so the statistics would show something. This worked well on my landscape as you can see below, so I integrated it into my hyperparameter tuner.

Before I go into the results, let me describe the whole data set – what it looks like in total, what the parts that we are trying to recognize, and the ground truth that we are training against:
Full Data Set: The data a set of mathematical functions. In this case, it’s a simple set of ten sin(x) waves of varying frequency. They all start at the same value, and evolve from there. The shortest wavelength is cyan, the longest is dark blue in the figure below. It’s a reasonable proxy for ten sensors that change over the course of a day, some quickly, some slowly:

Training Set: I take the above dataset, which has 200 elements and split it in two. This creates a training set or input vector of 100 elements and an output, “ground truth” vector that the system will be trained to recognize. So ten shapes will be trained to map to ten other shapes in one MLP network:

Ground Truth: This is the 100 sample vectors that we will be training the network to produce:

All Predictions: If you take the first random result of the evolver, you will get ten models that are identical except for the initial weights. In this case, the hyperparameters are number of layers, neurons per layer, batch size and epochs. The evolver initially comes up with a population of ten random genomes (in specified ranges, like 10 – 1000 neurons, with a step of 10). It then keeps the five best “genomes” and breeds and mutates 5 more. New genomes are in turn run 10 times to produce the statistics. The models associated with the best values are saved.
If we look at one of the initial models, before any evolution optimization you can see why this approach is needed. Remember, This variation is based solely on the different random initialization of the weights between layers. What you are looking at is the input vector being run through ten models that are used to calculate the statistical values of the ensemble. You can see that most values are pretty good, some are a bit off, and some are pretty bonkers.

Ensemble Average: On the whole though, if you take the average of all the ensemble, you get a pretty nice result. And, unlike the single-shot method of training, the likelihood that another ensemble produced with the same architecture will be the same is much higher.

Here’s the code to take the average:
avg_mat = np.zeros(self.test_mat.shape)
with os.scandir() as entries:
count = 1
for entry in entries:
if entry.is_file() or entry.is_symlink():
os.remove(entry.path)
elif entry.is_dir():
count += 1
print("loading: {}".format(entry.name))
new_model = tf.keras.models.load_model(entry.name)
self.predict_mat = new_model.predict(self.train_mat)
avg_mat = np.add(self.predict_mat, avg_mat)
avg_mat = avg_mat / count
This is not to say that the model is perfect. The orange curve at the top of the last chart is too low. This model had a mean accuracy of 67%. But this is roughly equivalent to my initial hyperparameter guesses. Let’s see what happens after 50 generations.
Five hours and 5,000 evaluations later, I have the full run of 50 generations. Things did get better. We end with a higher mean, but we also have a variance that does not steadily improve. This means that it’s possible that the architecture around generation 23 might actually be better:

Because all the values are saved in the spreadsheet, I can try those hyperparameters, but the system as I’ve written it only saves the “best” set of parameters. Let’s see what that best ensemble looks like as an ensemble when compared to the early run:

That is a lot better. All the related predictions are much closer to each other, and appear to be clustered around the right places. I am genuinely surprised how tidy the clustering is, based on the previous “All Predictions” plot towards the top of this post. On to the ensemble average:

That is extremely close to the “Ground Truth” chart. The orange line is in the right place, for example. The only error that I can see with a cursory visual inspection is that the height of the olive line is a little lower than it should be.
Now, I am concerned that there may be two peaks in this fitness landscape that we’re trying to climb. The one that we are looking for is a generalized model that can fit approximate curves. The other case is that the network has simply memorized the curves and will blow up when it sees something different. Let’s test that.
First, let’s revisit the training set. This model was trained with extremely clean data. The input is a sin function with varying frequencies, and the evaluation data is the same sin function, picking up where we cut off the training data. Here’s the clean data that was used to train the model:

Now let’s try noising that up, so that the model has to figure out what to do based on data that model has never seen before:

Let’s see what happened! First, let’s look at all the predictions from the ensemble:

The first thing that I notice is that it didn’t blow up. Although the paths from each model are somewhat different, each one got all the paths approximately right, and there is no wild deviation. The worst behavior (as usual?) is the orange band, and possibly the green band. But this looks like it should average well. Let’s take a look:

That seems pretty good. And the orange / green lines are in the right place. It’s the blue, olive, and grey lines that are a little low. Still, pretty happy with this.
So, ensembles seem to work very well, and make for resilient, predictable behavior in NN architectures. The cost is that there is much more time required to run many, many models through the system to determine which ensemble is right.
But if you want reproducible results, it’s a good way to go.