
Modifications
- 12.13.16: Initial post
- 12:16:16: Added reference to proposal and explicitly discussed explorer and exploiter types.
A web version of my Google Docs dissertation proposal is here. Blame them for the formatting issues. The section this is building on is Section 5.3.1. A standalone description of this task is here.
The first part of my dissertation work is to develop an agent-based simulation that exhibits information bubble/antibubble behavior. Using Sen and Chakrabarti’s Sociophysics as my guide, I’m working up the specifics of the model. My framework is an application (JavaFX, because that’s what I’m using at work these days). It’s basically an empty framework with a trivial model that allows clustering based on similar attributes such as color: 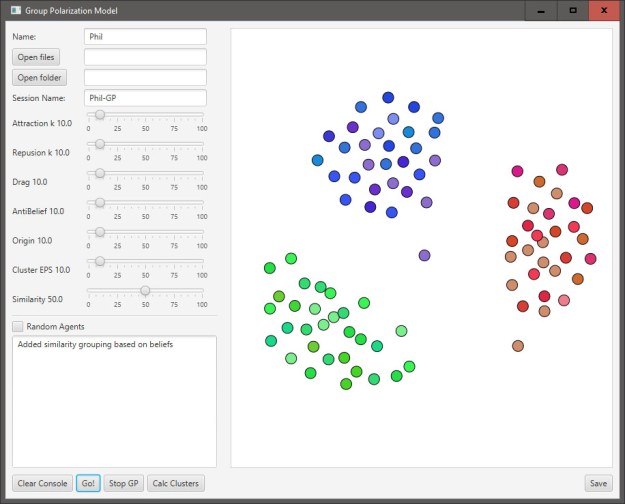
Going forward, I need to clarify and defend the model, so I’m going to be listing the components here.
Agent assumptions
- Agents get their information from global sources (news media). They have equal access, but visibility is restricted
- Agents are Explorers or Exploiters (Which may be made up of Confirmers and Avoiders)
- Agents have ‘budgets’ that they can allocate
- Finding sources has a cost. Sources from the social network has a lower cost to access
- Keeping a source is cheaper than getting a new one
- For explorers, the cost of getting a new source is lower than an exploiter.
- The ‘belief’ as a set of ‘statements’ appears to be valid
- The collection of statements and the associated values create a position in an n-dimensional hilbert space of information. Position and velocity should be calculable.
- Start at one dimension to reproduce prior opinion models
Network assumptions
- There are two items that we are looking for.
- The first is the network configuration over time. What nodes do agents connect to for their information.
- The second is the content of that information. For that, we’ll probably need some dimensionality reduction, such as NMF (look for a post on implementing this later). This is where we look for echo chambers of information, as opposed to the agents participating in them
- Adjustable to include scale-free, small world, and null configurations
- What about loops? Feedback could be interesting, since a small group that is semi-isolated could form into a very loud bubble that could lower the cost of finding information. So a notion of volume might be needed that emerges from a set of agreeing agents. This could be attraction, though I think I like an economic approach more?
- There is also a ‘freezing’ issue, where a stable state is reached where two cliques containing different states are lightly connected, but not enough that the neighbors in one clique can be convinced to change their opinion [Fig. 6.2, pg 135]
Measures
- Residual Energy: The difference between the actual energy and the known energy of the perfectly-ordered ground state (full consensus).
- Deviation from null network.
- Clustering as per community detection (Girard et. al)
Implementation details
- Able to be run multiple times with the same configuration but different seed
- Outputs to… something. MySql or Excel probably
- Visualization using t-SNE? Description plus Java implementation is here: https://lvdmaaten.github.io/tsne/
More to come as the model fleshes out.

Pingback: Phil 12.13.16 | viztales
Pingback: Notes on “Sociophysics, an Introduction” | Phlog